DocumateOCR-スキャンしたドキュメントから編集可能なテキストを抽出
Documate OCR strong>は、スキャンしたドキュメントから編集可能なテキストを抽出する機能を提供する画像処理アプリです。 JPG、PNG、TIFF、Wordなどのさまざまな種類のスキャンドキュメントで使用できます。 Documate OCR strong>は、コンピュータービジョンのアプローチを使用して、スキャンした画像から編集可能なテキストを抽出します。スキャンした画像のテキストを認識し、言語を判別して、最も可能性の高いテキストを返します。
最初にDocumateOCR strong>を起動すると、「ギャラリーモード」が表示されます。 " オプション。この機能を使用して、キャプチャしたドキュメントをギャラリーに保存する前に確認できます。
デバイスからドキュメントをキャプチャする
OCRを文書化する。 [スキャンして読む]オプションを使用してドキュメントをキャプチャできます。
ターゲットドキュメントの言語を選択します
からターゲット言語を選択します言語リスト。
光学式文字認識( OCR strong>)を実行する
[スキャンして読み取る]オプションが有効になっている場合、リストからターゲットドキュメントを選択できるようになります。 p>
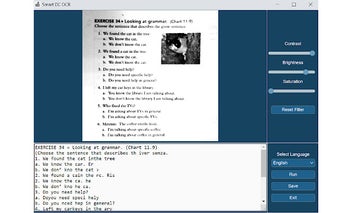
[ OCR]メニューが表示されます。ここでは、母国語を選択できます。ドキュメントに複数の言語が含まれている場合は、複数の言語を選択できます。 p>
ドキュメントをギャラリーに保存
保存するにはキャプチャしたドキュメントの場合は、[ OCR]メニューの[保存]オプションを使用する必要があります。